
 Dilaver DEMİREL
Dilaver DEMİREL
Docker ile CI (Continious Integration) Ortamı Nasıl Kurulur?
Örnek bir pipeline oluşturmak istiyorum. Bu pipeline içerisindeki adımları aşağıdaki gibi belirleyebiliriz;
Not: Bu örnek uygulama maven projesi olarak oluşturulmuştur.
-
Kodların checkout edilmesi
-
Projenin build(maven) edilmesi
-
Projedeki unit testlerin çalıştırılması
-
Statik kod analizinin çalıştırılması
Bu işlemleri yapabilmek için ihtiyacım olanları aşağıdaki gibi sıralayabilirim;
-
Docker kurulu bir bilgisayar
-
Jenkins için docker image
-
Projeyi build ederken kullanacağım maven docker image
-
Statik kod analizini işleyip görselleştirmek için SonarQube docker image
Docker kurulu olan bilgisayar olduğunu varsayarak devam edersek 2. adıma geçebilirim. Bu adımda kullanacağım docker image “jenkinsci/blueocean”. Fakat benim kodları çekebilmem için gerek duyduğum SSH işlemleri için docker image’nda bazı değişiklikler yapmam gerekti. Container içerisinden kolayca SSH bağlantısı yapabilmem için SSH private key’i image’e ekleyip aynı zamanda bağlanacağım adresi de “known_hosts”a eklemem gerekli.
Buna bağlı olarak docker file aşağıdaki gibi oluşuyor;
FROM jenkinsci/blueocean
ARG ssh_prv_key
ARG ssh_pub_key
USER root
RUN mkdir -p /root/.ssh && \
chmod 0700 /root/.ssh && \
ssh-keyscan -p 2022 [host-name] > /root/.ssh/known_hosts
RUN echo "$ssh_prv_key" > /root/.ssh/id_rsa && \
echo "$ssh_pub_key" > /root/.ssh/id_rsa.pub && \
chmod 600 /root/.ssh/id_rsa && \
chmod 600 /root/.ssh/id_rsa.pub
USER jenkins
Aşağıdaki bölüm [host-name] ile belirtilen adresi “known_hosts” dosyasına eklemeyi sağlar.
RUN mkdir -p /root/.ssh && \
chmod 0700 /root/.ssh && \
ssh-keyscan -p 2022 [host-name] > /root/.ssh/known_hosts
Aşağıdaki bölüm ise “$ssh_prv_key” ve “$ssh_pub_key” parametreleri ile verilen SSH private ve public keylerini “.ssh” dizinine eklemeyi sağlar.
RUN echo "$ssh_prv_key" > /root/.ssh/id_rsa && \
echo "$ssh_pub_key" > /root/.ssh/id_rsa.pub && \
chmod 600 /root/.ssh/id_rsa && \
chmod 600 /root/.ssh/id_rsa.pub
Docker image build etmek için aşağıdaki komutu kullanabilirsiniz;
docker build -t custom-jenkins-blueocean --build-arg
ssh_prv_key="$(cat /[your-path]/id_rsa)" --build-arg
ssh_pub_key="$(cat /[your-path]/id_rsa.pub)" --squash .
Yeni oluşturduğumuz image üzerinden bir container çalıştırmak için aşağıdaki komutu kullanabilirsiniz;
docker volume create jenkins-data
docker run --name my-jenkins -u root --rm -d -p 8080:8080 -p 50000:50000 -v jenkins-data:/var/jenkins_home -v /var/run/docker.sock:/var/run/docker.sock custom-jenkins-blueocean
docker logs -f my-jenkins
Jenkins çalıştıktan sonra admin olarak açıldığından emin olmak için admin password istiyor. Bu bilgiyi alabilmek için aşağıdaki adımları izleyebilirsiniz;
docker exec -it my-jenkins bash
vi /var/jenkins_home/secrets/initialAdminPassword
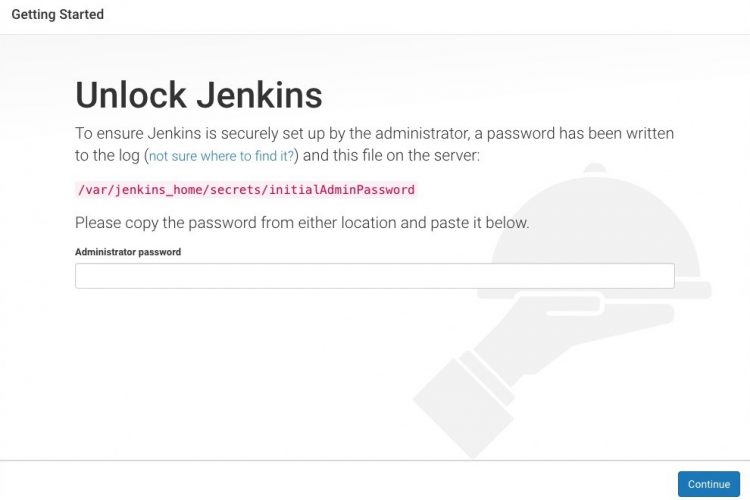
Sonraki adımda jenkins için default plug-inleri kurmasını belirtip geçebiliriz. Artık Jenkins kullanıma hazır durumda.
Artık Jenkins ortamının hazır olduğunu gördük. Bundan sonraki adım projemizi CI/CD işlerini yapacak pipeline oluşturmak. Test etmek için aşağıdaki repoyu kullanabilirsiniz;
https://github.com/dilaverdemirel/simple-java-maven-app
Bu repo içerisindeki Jenkinsfile bizim pipeline’nımızı otomatik oluşturmamızı sağlayacak.
pipeline {
agent {
docker {
image 'maven:3-alpine'
args '-v /root/.m2:/root/.m2 -v /var/run/docker.sock:/var/run/docker.sock --privileged'
}
}
stages {
stage('Build') {
steps {
sh 'mvn -B -DskipTests clean package'
}
}
stage('Test') {
steps {
sh 'mvn test'
}
post {
always {
junit 'target/surefire-reports/*.xml'
}
}
}
stage('Deliver') {
steps {
sh './jenkins/scripts/deliver.sh'
}
}
}
}
Scripti incelediğimizde;
agent {
docker {
image 'maven:3-alpine'
args '-v /root/.m2:/root/.m2'
}
}
yukarıdaki bölüm pipeline scriptinde tanımlı olan “stage”leri çalıştıracağımız ortamı bize sağlar. Stage’ler bir “maven:3-alpine” image ile oluşturulan docker conrainer içerisinde çalıştırılır. “maven:3-alpine” image bize Maven 3 kurulu bir ortam sağlar. Amacımız maven projesi olarak oluşturulmuş olan projemizi build/test/deliver adımlarından geçirip belirlediğimiz kontrolleri ve işleri yapmamız. Bunun için maven tooluna ihtiyacımız vardı, bunu da “maven:3-alpine” image ile hallettik.
Bu sayede bir maven kurulumu yapmadan yine docker ile projeyi build ve test ettik.
Bu noktada eğer custom bir maven repository kullanıyorsanız maven “settings.xml” dosyasını değiştirmeniz gerekecektir. Bunun için ise aşağıdaki docker file’ı kullanabilirsiniz;
#Dockerfile
FROM maven:3.6.1-jdk-8-slim
COPY settings.xml /usr/share/maven/conf/
Dockerfile’in olduğu dizinde maven için gerekli olan “settings.xml” dosyası da olmalıdır. Aşağıdaki komut ile image build edebilirsiniz;
docker build -t maven-jdk-8-slim .
Oluşturduğunuz custom image’ı kullanmak için “Jenkinsfile” içerisindeki agent bölümünü aşağıdaki gibi değiştirmelisiniz;
agent {
docker {
image 'maven-jdk-8-slim'
args '-v /root/.m2:/root/.m2'
}
}
Sonuç olarak docker ile jenkins ortamını kurduk ve yine maven docker image ile projemizi build ettik. Docker dışında farklı bir araç kurulumunu manuel olarak yapmadık.
Video Nedir?
Arka arkaya sıralanmış bir çok imajın hareketli gibi algılanan bir görsel oluşturmasıdır. Videolar için FPS(Frame per second) değeri çok önemlidir.
Aynı zamanda görüntünün iletimi sırasında sıkıştırılması da günümüz teknolojilerine çok büyük kolaylık sağlıyor. Örneğin;
1 Piksel = 8 bit * 3(RGB) => 24 bit
-
1024×1024 piksel bir görüntü yaklaşık 24 Mbit yer kaplar.(1K*1K*24)
-
Bu görüntüyü sıkıştırmadan/kodlamadan iletiyor olsaydık saniyede 1 kare için(1 FPS ) 24Mbit bant genişliğine ihtiyacımız olurdu.
-
Bu hareketli görüntüler için kabul edilemez bir FPS değeridir.
Şimdi Görüntü ve Video hakkında bilgi edindiğimize göre nesne algılamanın algoritmik tarafına geçebiliriz.
CNN(Convolitional Neural Network)
-
CNN(ConvNet) algoritması görüntü ve videolar üzerinde nesneleri algılamak için kullanılan bir algoritmadır.
-
CNN algoritmasına verilen görüntüleri birbirinden ayırt etmek(öğrenmek) için görüntü üzerindeki nesnelerin benzersiz özelliklerini (Feature) kullanırlar.
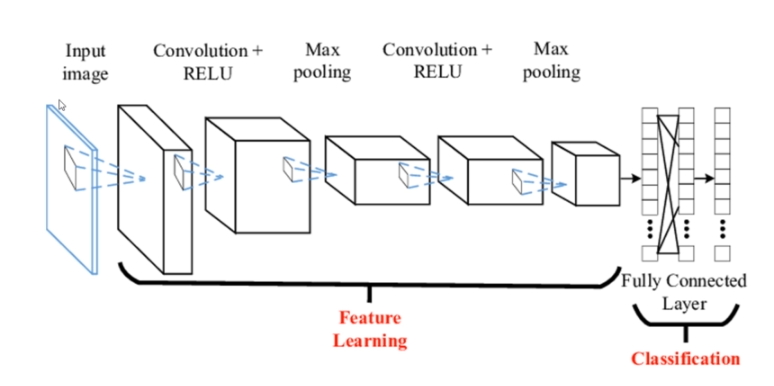
CNN algoritması başlı başına bir yazı olarak ele alınabilir. Konumuz sadece CNN olmadığından, algoritma hakkında bilinmesi gereken temel bilgilerden bahsedelim.
Yapısı;
-
Convolution Layer : Image/Frame üzerindeki benzersiz özellikleri saptar.
-
Non-Linearity Layer : Görüntü matrisi bir aktivasyon fonksiyonundan geçirilerek imaj normalize edilir. Seçilen aktivasyon fonksiyonu biraz sonra gerçekleşecek olan sinir ağı eğitiminin hızını etkiler.
-
Pooling Layer : Matrisin ağırlık sayısını azaltır. Bazı kullanıcılar pooling katmanını kullanmak yerine convolution katmanında kullanmış olduğu filtre matrisinin boyutunu arttırırlar.
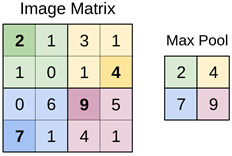
-
Fully-Connected Layer : Bu katmana kadar gerçekleşen olaylar görüntünün yapay sinir ağına hazırlanması aşamasıdır. Bu katman ise sistemin eğitildiği yani yapay sinir ağının çalıştığı katmandır. CNN algoritmasının çıkışı bu katmandır denilebilir.
Şimdi yazımızın başrol oyuncusu olan YOLO’ya geçebiliriz 🙂

YOLO Nedir?
-
YOLO konvolüsyonel sinir ağları kullanarak nesne tespiti yapan bir algoritmadır. Açılımı ‘’You Only Look Once’’ demektir.
-
Sebebi ise algoritmanın nesne tespitini oldukça hızlı bir şekilde ve tek seferde yapabiliyor olmasıdır.
-
-
YOLO algoritmasının diğer algoritmalardan daha hızlı olmasının sebebi resmin tamamını tek seferde nöral bir ağdan geçiriyor olmasıdır.
-
YOLO algoritması görüntüler üzerinde tespit ettiği nesnelerin çevresini bounding box ile çevreler.
-
YOLO kendisine girdi olarak verilen görüntüyü NxN’lik ızgaralara böler. Bu ızgaralar 5×5,9×9,17×17… olabilir.
-
Her ızgara kendi içerisinde nesne olup olmadığını ve nesne var olduğunu düşünüyorsa merkez noktasının kendi alanında olup olmadığını düşünür.
-
Nesnenin merkez noktasına sahip olduğuna karar veren ızgara o nesnenin sınıfını, yüksekliğini ve genişliğini bulup o nesnenin çevresine bounding box çizmelidir.
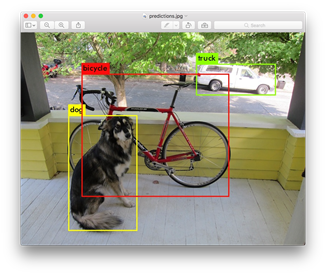
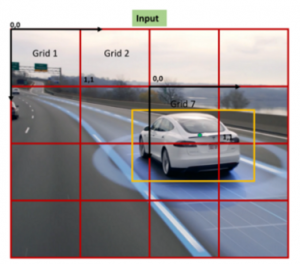
-
Birden fazla ızgara, nesnenin kendi içerisinde olduğunu düşünebilir. Bu durumda ekranda gereksiz bounding box’lar oluşur.
-
Bütün bounding boxların güven skoru vardır.
-
Bu durumu engellemek için Non-Maximum Suppression algoritması kullanılır.
-
Kısaca Non-max Suppression algoritması görüntü üzerinde tespit edilen nesneler için çizilen bounding boxlardan güven değeri en yüksek olanı ekrana çizer.


Aşağıdaki grafiklerde YOLO ve diğer bazı algoritmaların MS COCO data set’i için object detection performanslarını görebiliriz.
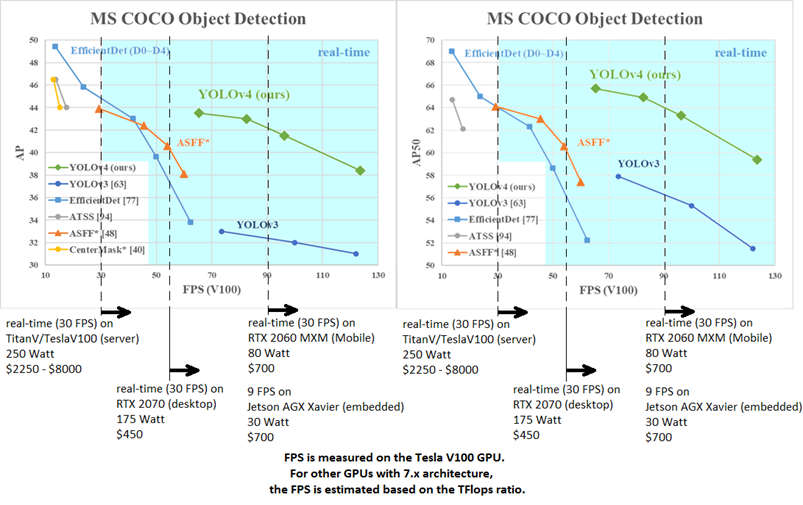
Grafiklerde de göründüğü gibi sınıflandırıcı sayısının eşit olduğu bir case düşünürsek YOLOv4 rakiplerine göre neredeyse 3 kat fark atmış durumda.
Şimdi YOLO ile nesne tanıma aşamalarından kısaca bahsedelim. Örnek olarak Maskeli ve Maskesiz Yüzleri tespit eden bir projeyi inceleyelim.
1-)Data Toplama/Etiketleme
Data etiketleme işlemini https://www.makesense.ai/ üzerinden yapabilirsiniz. Etiketleme işlemi algoritmanın maskeli ve maskesiz insanları ayırt edip kendi kendini eğitebileceği train datasını kendisine verebilmemiz için önemlidir. Make Sense dışında görüntü etiketleme yapabileceğiniz bir çok ortam bulabilirsiniz. Ben tercihimi etiketleme sonucundaki datayı YOLO’nun istediği formatta verebilen Make Sense’den yana kullanıyorum. Aşağıda etiketleme aşaması için örnek görüntüleri görüyoruz.
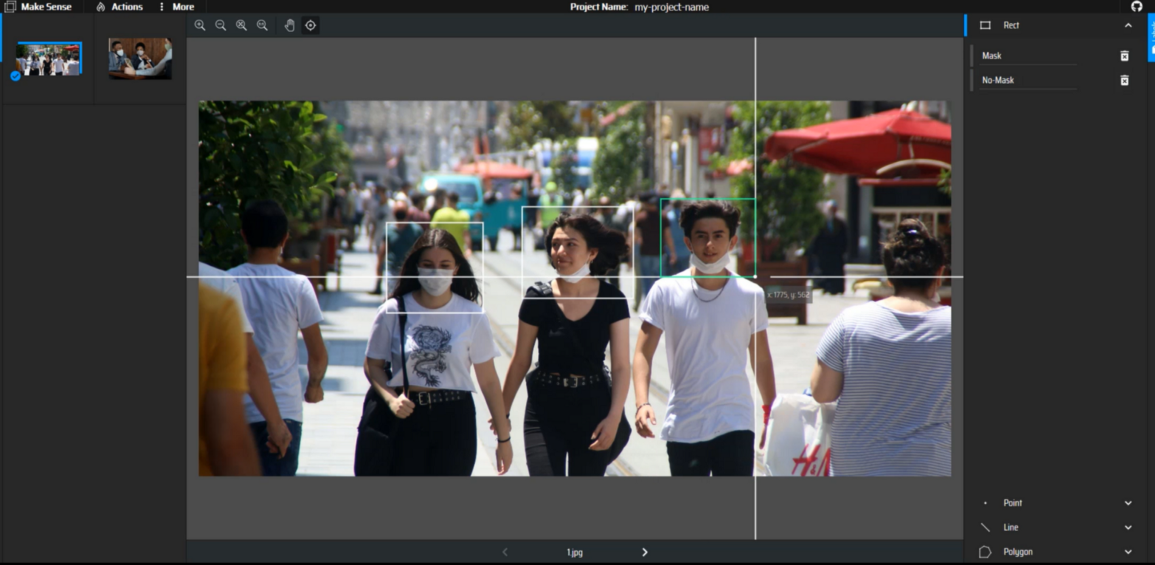
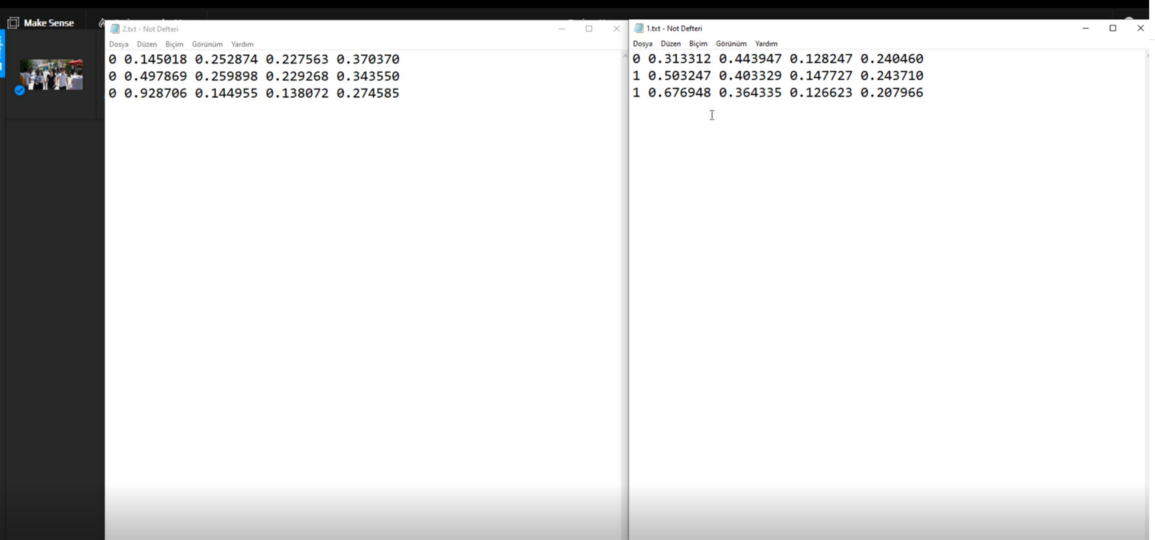
Örnek olması açısından 2 adet görüntü etiketledim ve sonucu YOLO formatında export ettiğimde aşağıdaki şekilde 2 görüntü için 2 farklı matrise sahip oldum.
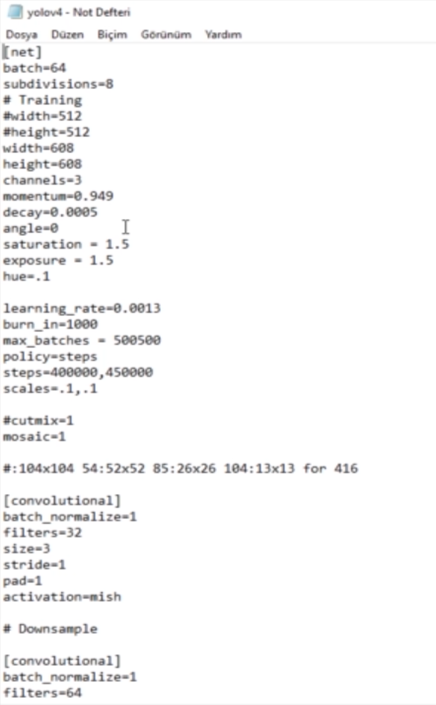
Görüntüleri etiketledikten sonra DarkNet aracılığı ile Google Colab üzerinden kendi YOLO modelimi eğittim. Eğitim aşamaları için bazı ekran görüntülerini sizler ile paylaşıyorum.
-
YOLO algoritmasının çalıştırılabilmesi için Darknet bizden bazı dosyalar beklemektedir. Bunlardan bir tanesi de .cfg dosyasıdır.
-
Config dosyası YOLO içerisindeki Sinir ağının başarısını,hızını vs etkileyecek özellikleri bizden talep eder.
-
YOLO’nun bizden beklediği bir başka dosya ise .names dosyası.Names içerisinde sınıfların adlarını tutar.Maske tespiti uygulaması için Mask ve No-Mask olmak üzere 2 class vardır.
-
Ayrıca bütün dosyaların DarkNet klasöründeki konumunu belirten .data uzantılı dosyayı da bizden talep eder.
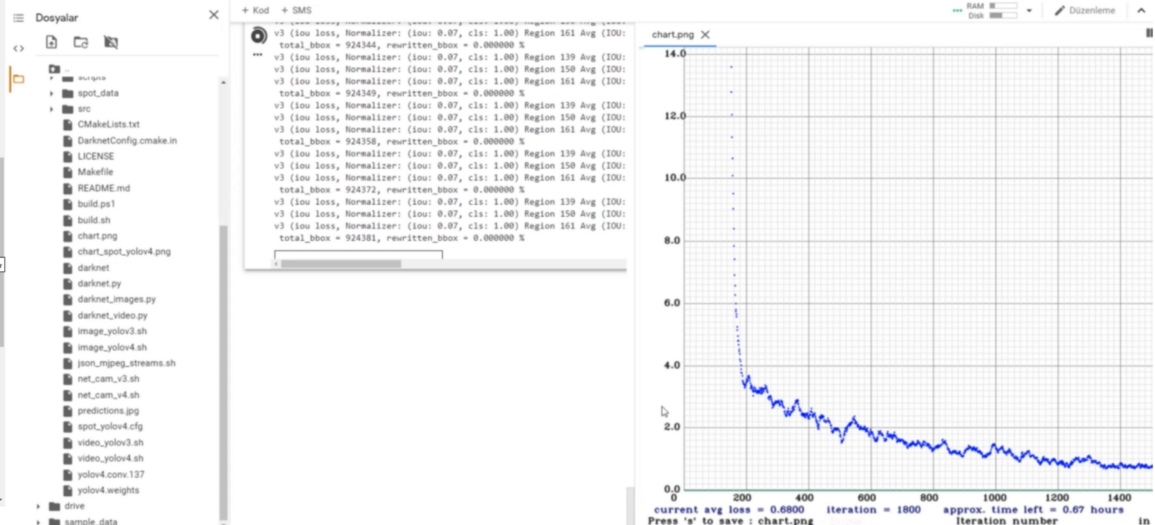
Bir eğitimin başarısını eğitim sonrası oluşan loss grafiğinden anlaşılabilir. Eğer YOLO modelimiz için çok fazla data train edip ve yapay sinir ağımızın iterasyon sayısını çok fazla arttırırsak
sistem Over Train(Aşırı Öğrenme) olabilir. Bu da modelimizde yaşanmasını istemediğimiz bir durum.
Eğitim aşamasını tamamlayıp .weights uzantılı dosyamıza sahip olduğumuzu varsayıyoruz. Artık modelimiz hazır.
Data etiketleme eğitim vs. gibi işlemler ile uğraşmak sıkıcı olabilir. Alternatif olarak bir başkası tarafından eğitilmiş bir modeli kullanabilirsiniz. Maske basit 2 sınıfa sahip bir örnek olduğu için belki bilmediğimiz bir modeli kullanabiliriz fakat özel durumlar ve unique bir konu için nasıl eğitildiğini bilmediğimiz bir modeli kullanmak iyi bir tercih olmayabilir.
Bu aşamaya kadar hepimizin Maske Tanıma için weights ve config dosyalarımızın elimizde olduğunu kabul ediyorum.
Maske tanıma işlemini local kamera ile real time olarak yapabildiğim programa aşağıdan ulaşabilirsiniz.
Github : https://github.com/alperenyildiz/mask-detection
import cv2
import numpy as np
whT = 320
cap = cv2.VideoCapture(0)
confThreshold=0.5
nmsThreshold=0.3
classFile="maske.names"
classNames=[]
with open(classFile,"rt") as f:
classNames=f.read().rstrip("\n").split("\n")
modelConfiguration="maske.cfg"
modelWeights="maske_final.weights"
model=cv2.dnn.readNetFromDarknet(modelConfiguration,modelWeights)
model.setPreferableBackend(cv2.dnn.DNN_TARGET_CPU)
model.setPreferableTarget(cv2.dnn.DNN_TARGET_CPU)
def findObject(detectionLayers,img):
hT,wT,cT=img.shape
bbox=[] #sınırlayıcı kutularımızı tutan liste
classIds=[] #sınıflarımızı tutan id listesi
confs=[] #Bulunan nesnelerin güven değerini tutan listemiz
for detectionLayer in detectionLayers:
for objectDetection in detectionLayer:
scores=objectDetection[5:]
classId=np.argmax(scores)
confidence=scores[classId]
if confidence>confThreshold:
w,h=int(objectDetection[2]*wT),int(objectDetection[3]*hT)
x,y=int((objectDetection[0]*wT)-w/2),int((objectDetection[1]*hT)-h/2)
bbox.append([x,y,w,h])
classIds.append(classId)
confs.append(float(confidence))
#Non maxiumum suppression ;
indices=cv2.dnn.NMSBoxes(bbox,confs,confThreshold,nmsThreshold)
for i in indices:
i=i[0]
box=bbox[i]
x,y,w,h=box[0],box[1],box[2],box[3]
if classNames[classIds[i]].upper() == "NO-MASK":
g,b,r = 0,0,255
else:
g,b,r = 0,255,0
cv2.rectangle(img,(x,y),(x+w,y+w),(g,b,r),3)
cv2.putText(img, f'{classNames[classIds[i]].upper()} {int(confs[i] * 100)}%',
(x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (g,b,r), 2)
while True:
success,img=cap.read()
blob=cv2.dnn.blobFromImage(img,1/255,(whT,whT),[0,0,0],1,crop=False) #[img,scale factor,boyut,]
model.setInput(blob)
layerNames=model.getLayerNames()
outputLayers=[layerNames[i[0]-1] for i in model.getUnconnectedOutLayers()]
detectionLayers=model.forward(outputLayers)
findObject(detectionLayers,img)
#cv2.namedWindow("Mask Detection", cv2.WINDOW_NORMAL)
#cv2.flip(img,1)
cv2.imshow("Mask Detection",img)
k = cv2.waitKey(20) & 0xFF
if k == 27:
break
cv2.waitKey(50)